Создавайте фото и видео генерации в одном месте
Здесь собраны лучшие нейросети в одном месте. Выбирайте любую модель - от самых быстрых и дешёвых до топовых по качеству.
Как сделать длинное видео в нейросети - 30 секунд и больше

Автор - Пётр Васильев
Разработчик ИИ-сервиса

Вы открываете Kling или другой AI-генератор, вводите промт, ждете - и получаете 5-10 секунд красивой картинки. Иногда 20. Дальше стена. Покупаете больше лимитов, а там те же 10 секунд.
Большинство людей решают, что длинное AI-видео - это "пока не для всех" и закрывают вкладку. Зря. Инструменты есть, пайплайны работают, 60-секундный рекламный ролик из нейросети стоит $5-50 против $5 000-50 000 при традиционном продакшне. Разница - в том, как именно устроен процесс. И вот этот процесс мы сейчас разберём.
Почему нейросети не делают длинные видео сразу
Это не маркетинговое решение и не способ заставить платить больше.
Видео - это последовательность кадров, и когда модель генерирует их один за другим, она не "помнит" предыдущие сцены так, как вы видите их на экране. Ошибки накапливаются: персонаж начинает менять лицо, освещение плывёт, фон ведёт себя непредсказуемо. Уже через 15-20 секунд чистой генерации это становится заметно. С увеличением длины ошибки не просто растут - они умножаются, потому что каждый новый кадр опирается на предыдущие, уже немного "сдвинутые".
Есть и вычислительная сторона. Одна секунда в 1080p - это 24-48 кадров, каждый из которых модель выстраивает с учётом предыдущих. Для коротких клипов это решаемо, для минуты - совсем другая история по затратам на инфраструктуру. GPT-2 в своё время генерировал короткие абзацы, GPT-4 пишет книги - с видео та же траектория, просто с задержкой в несколько лет.
Поэтому правильный вопрос - не "какую модель использовать, чтобы она сразу делала длинное видео", а "как организовать работу так, чтобы получить нужный хронометраж из коротких блоков". Логика та же, что в монтаже обычного кино: никто не снимает сцену одним непрерывным часовым планом.
Метод первый: Extend и склейка по последнему кадру
Самый очевидный путь - расширять клип итеративно.
У большинства моделей есть функция Extend или её аналог: модель берёт последнюю секунду вашего видео и генерирует продолжение. Kling V3 Omni Video и Kling 2.6 доходят до 3 минут через эту функцию. Veo 3.1 - до 148 секунд через цепочку из 20 расширений по 7 секунд.
Детали, которые определяют, получится у вас связное видео или лоскутное одеяло.
Первое - расширяйте короткими шагами. Вместо 5 секунд за раз - 1-2. Каждое расширение опирается только на самые последние кадры как контекст, и чем короче шаг, тем точнее модель воспроизводит стиль и движение. Медленнее, но результат заметно чище.
Второе - заканчивайте клип на "якорном" моменте перед расширением. Статичная поза персонажа, стабильное освещение, никаких объектов на выходе из кадра. Если последняя секунда - хаотичное движение или переходная сцена, расширение потеряет нить. У Veo 3.1 в документации прямо написано: последняя секунда исходного клипа - критический контекст для продолжения.
Третье - у Kling качество деградирует примерно после 30-40 секунд расширений. Это не баг - каждый новый блок чуть дальше от оригинала. Для роликов до минуты Kling справляется хорошо. Для более длинного контента лучше делать несколько независимых цепочек и монтировать их.
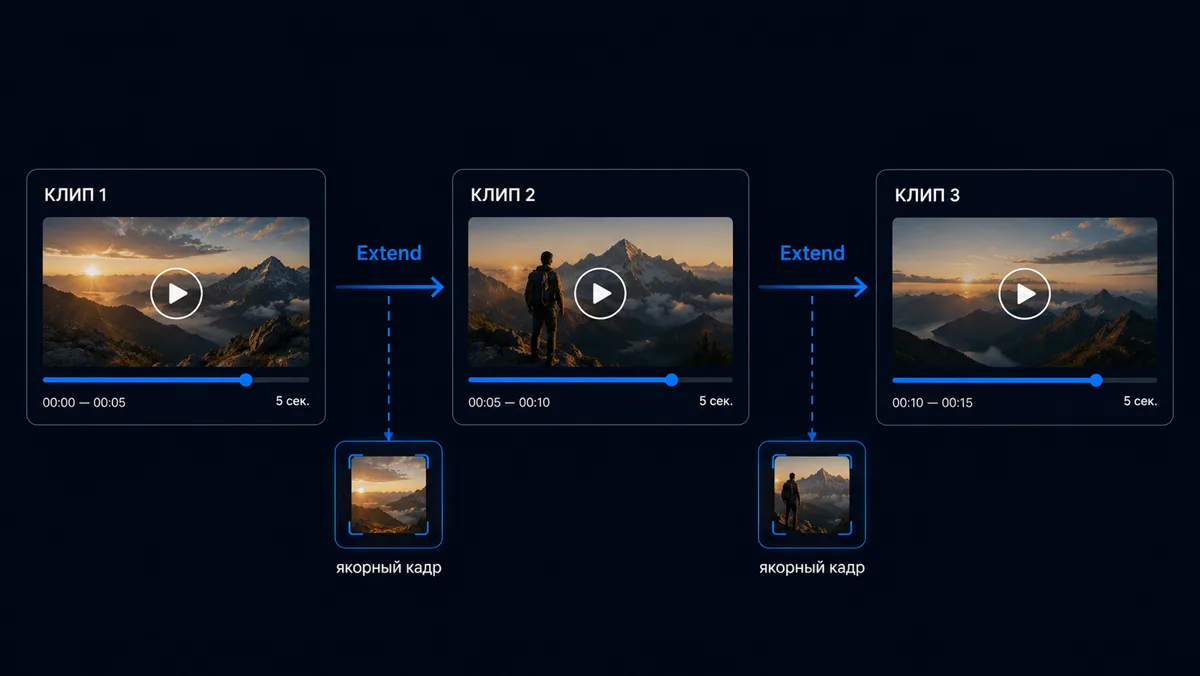
Метод второй: якорный кадр и Image-to-Video
Это самый недооцененный метод. И именно он решает главную проблему длинного видео - консистентность.
Вместо того чтобы генерировать видео из текстового промта, сначала создаете одно референсное изображение - и потом каждый клип "прикрепляете" к нему. Модель получает визуальный якорь: лицо персонажа, стиль освещения, цветовую палитру. Всё, что выходит за рамки якоря, она старается не генерировать.
Для создания референсного изображения в стиле под ролик хорошо подходит Flux 2 Pro - фотореалистичная детализация, референсы принимает. Дальше изображение идёт в Kling V3 Omni Video или Seedance 2 через Image-to-Video. В Kling есть функция Element Binding: загружаете 3-4 фотографии персонажа с разных ракурсов - анфас, профиль, три четверти - и модель фиксирует черты на уровне геометрии. Потом генерируете десятки клипов с этим персонажем, и он будет узнаваем в каждом.
Для маркетинга это важнее, чем кажется. Рекламный ролик с продуктом или брендовым персонажем должен быть консистентным, иначе это просто набор красивых, но несвязанных кадров. Image-to-Video через якорное изображение даёт именно это.
Практикующие создатели контента говорят одно и то же - никогда не идти от текстового промта сразу к видео. Сначала - стайлфрейм, потом - анимация. Это добавляет один шаг, но убирает 80% проблем с консистентностью.
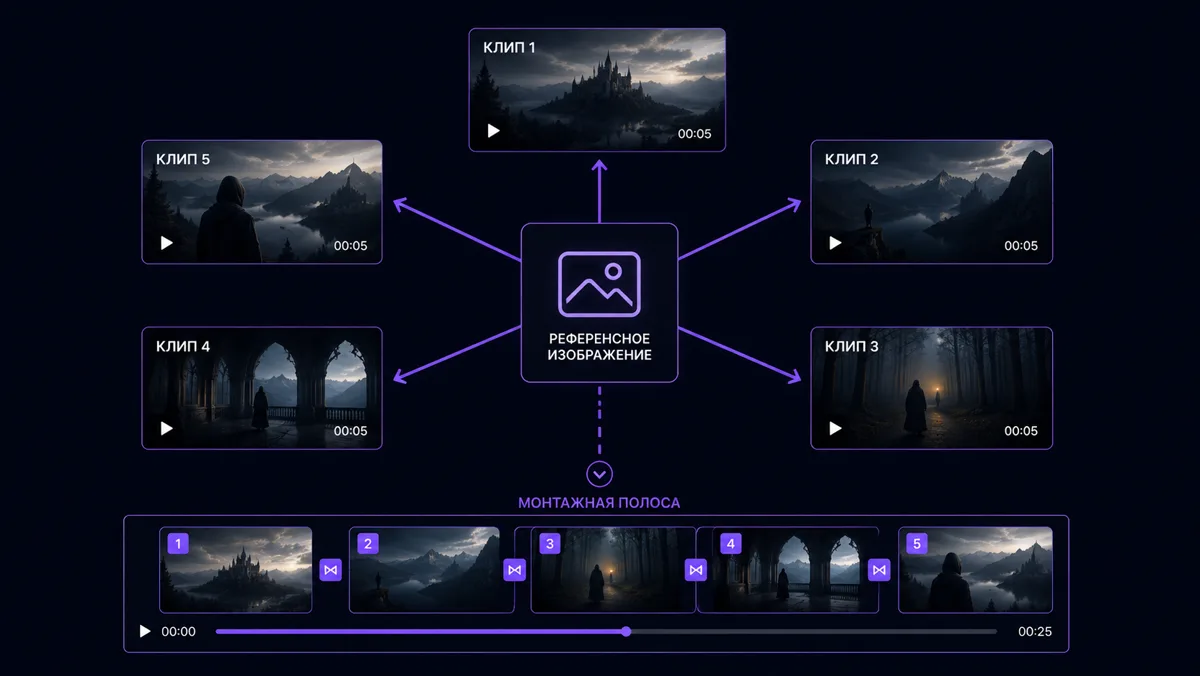

Метод третий: делить до начала генерации
Если есть чёткое представление о том, каким должен быть ролик, самый надежный способ - разбить его на сцены до того, как запущена первая генерация.
Берёте сценарий на 60 секунд и делите его на 8-12 сцен по 5-8 секунд. Для каждой пишете отдельный промт с учетом визуального якоря. Генерируете сцены независимо, отбираете лучшие дубли и собираете в монтаже. Прямая аналогия со съемочным процессом, только без камеры и съемочной группы.
У подхода есть еще одно практическое преимущество - параллельность. Пока рендерится сцена 2, можно запустить генерацию сцен 4 и 6 одновременно. Профессиональные команды именно так сокращают общее время производства.
Главное при написании промтов для отдельных сцен - последовательно передавать описание визуального стиля. Если в первой сцене "золотой час, тёплый свет, кинематографичная камера", это описание должно быть в каждом последующем промте. Модель не видит предыдущих клипов и ничего не "помнит".
Метод четвертый: пайплайн с монтажом
Когда клипы готовы, их нужно собрать. И это отдельный навык, который многие недооценивают.
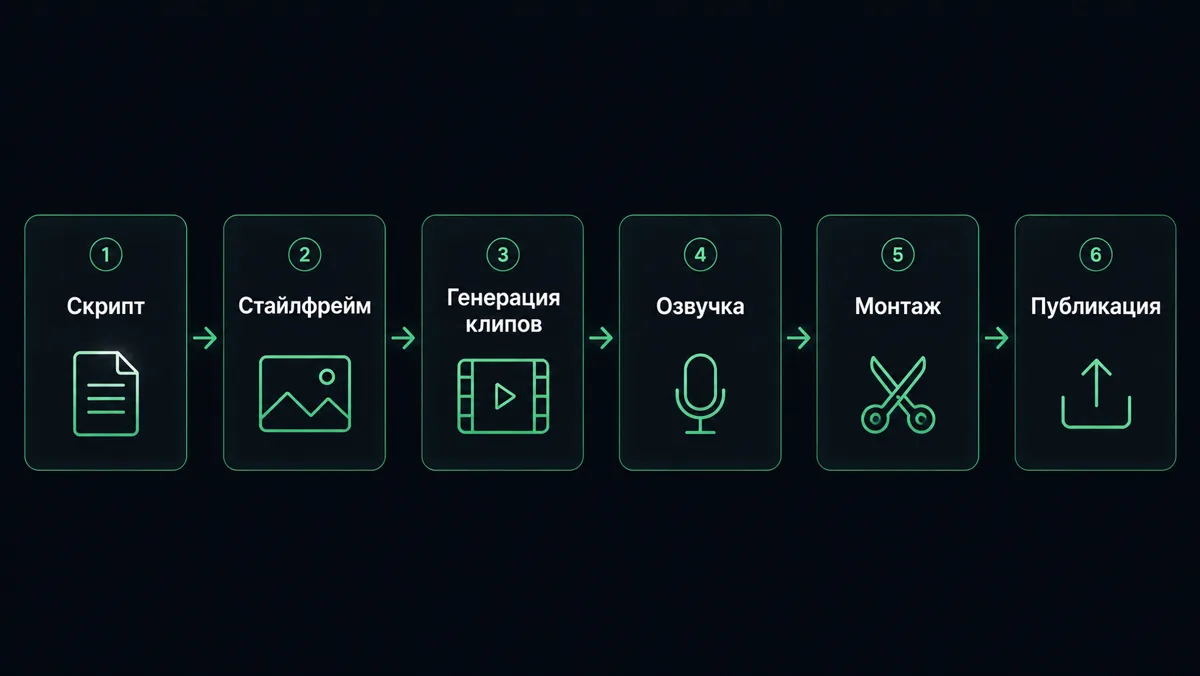
Типичный пайплайн для 60-секундного ролика: скрипт пишется через GPT 5.2 или Gemini 2.5 Flash, стайлфреймы для каждой сцены генерируются в Flux 2 Pro, видеоклипы делаются в Kling V3 Omni Video или Veo 3.1 Quality через Image-to-Video, озвучка - в ElevenLabs, музыка - в Suno, монтаж - в CapCut или DaVinci Resolve. Время на один ролик - 2-4 часа против 2-4 недель при традиционном продакшне.
CapCut подходит для быстрых задач: скрипт вставляется прямо в интерфейс, инструмент сам разбивает его на сцены, добавляет субтитры и делает черновик. Это не замена полному пайплайну, но хорошая точка входа. DaVinci Resolve - для тех, кому нужен контроль над цветокоррекцией.
Один момент, который обычно упускают. Склеивая клипы, нужно работать с переходами. Резкая склейка двух AI-клипов часто выглядит искусственно, особенно если в сценах разный уровень освещения. Кросс-фейд в 3-5 кадров почти всегда решает это. Текст, графика, цветовые флэши на переходах - маскируют швы ещё лучше.
Вопросы и ответы
Почему персонаж меняется от сцены к сцене и как это исправить?+
Это главная проблема при склейке клипов. Без референсного изображения каждый новый промт - это новая "интерпретация" персонажа моделью. Решения два. Первое - всегда использовать Image-to-Video с одним и тем же стартовым изображением для каждой сцены. Второе - в Kling использовать Element Binding: загрузить несколько фотографий персонажа с разных ракурсов, и модель зафиксирует его внешность. Полной идентичности между клипами всё равно не будет, но разница сократится до уровня, который не бросается в глаза.
Как написать промт для длинного ролика - один большой или несколько коротких?+
Один большой промт не работает - модели не умеют генерировать видео по многостраничному сценарию. Правильный подход: один промт на одну сцену. Каждый промт должен описывать конкретный момент: кто в кадре, что происходит, как движется камера, какой свет. Визуальный стиль - "золотой час", "кинематографичная камера", "тёплые тона" - прописывается в каждом промте отдельно, даже если он уже был в предыдущем. Модель не видит предыдущие клипы и не переносит стиль автоматически.
Что делать, если лицо или объект "плывёт" в середине клипа?+
Это одна из самых частых проблем. Модель не удерживает геометрию лица стабильно без явной инструкции. Первое решение - добавить в промт фразу "сохрани черты лица" или "no face change" (работает на большинстве моделей). Второе - загрузить референсное фото персонажа и переключиться с text-to-video на Image-to-Video. Третье - добавить negative prompt: "extra fingers, deformed hands, blurry face, plastic skin, watermark" - на тестах это вдвое снижает количество артефактов. Если лицо плывет уже после 5-6 шагов Extend-цепочки, это сигнал остановиться и начать новую цепочку с более четким стартовым кадром.
Вас может заинтересовать
Все статьи
Создание рилсов с помощью нейросетей: пошаговое руководство
Пошаговый процесс создания Reels с помощью нейросетей: от идеи и сценария до генерации кадров, видео и финального монтажа.
Генерация изображений в СhatGPT - инструкция с промтами
Пошаговая инструкция по генерации изображений в ChatGPT: три сценария работы, структура промта и готовые примеры для карточек товара, баннеров, аватаров и фотосессий.

Как создать многостраничный комикс с помощью нейросети ChatGPT и GPT Image 2
Пошаговый гайд по созданию многостраничного комикса с нейросетями: библия проекта, промты, консистентность персонажей, сборка страниц и реальные примеры.